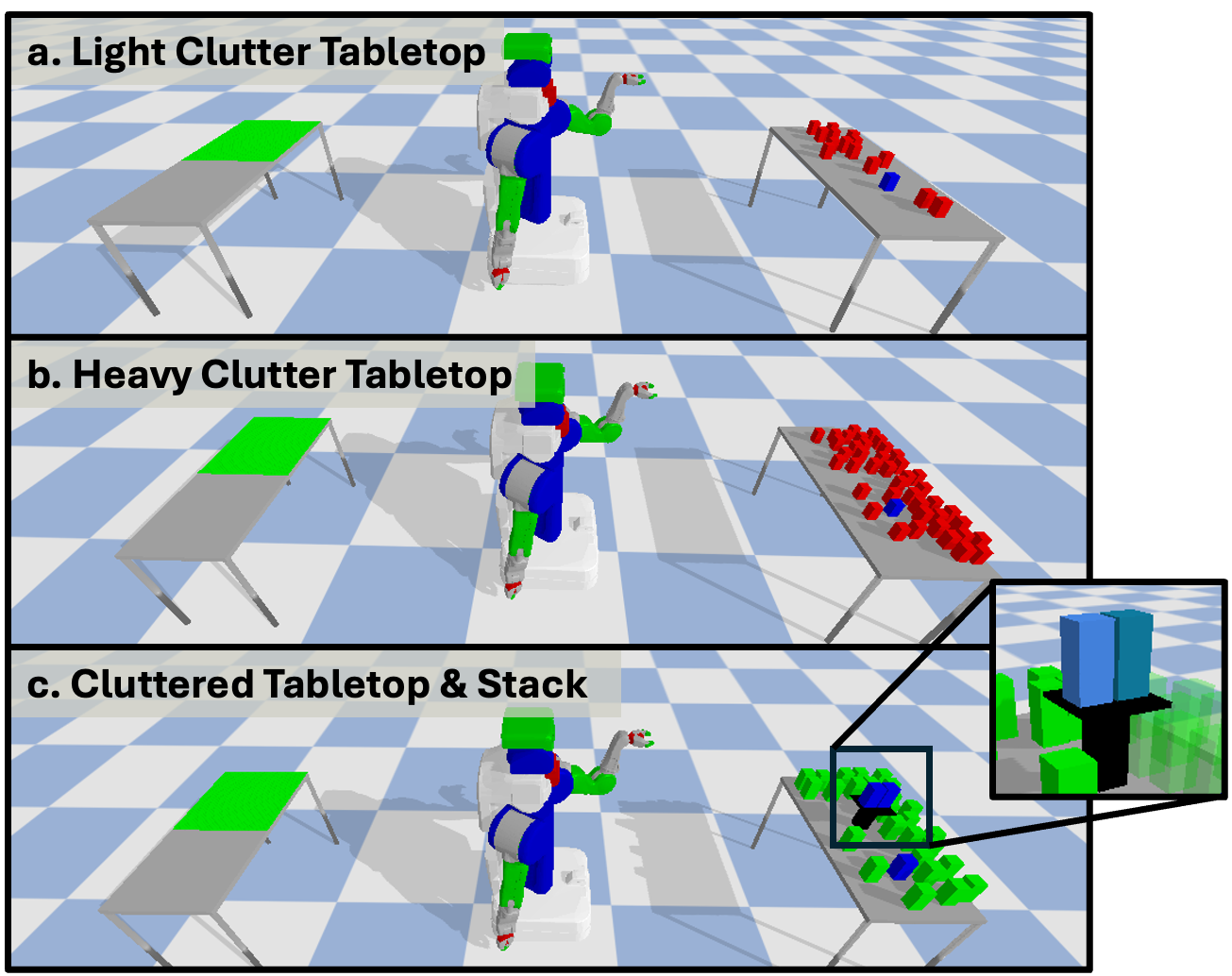
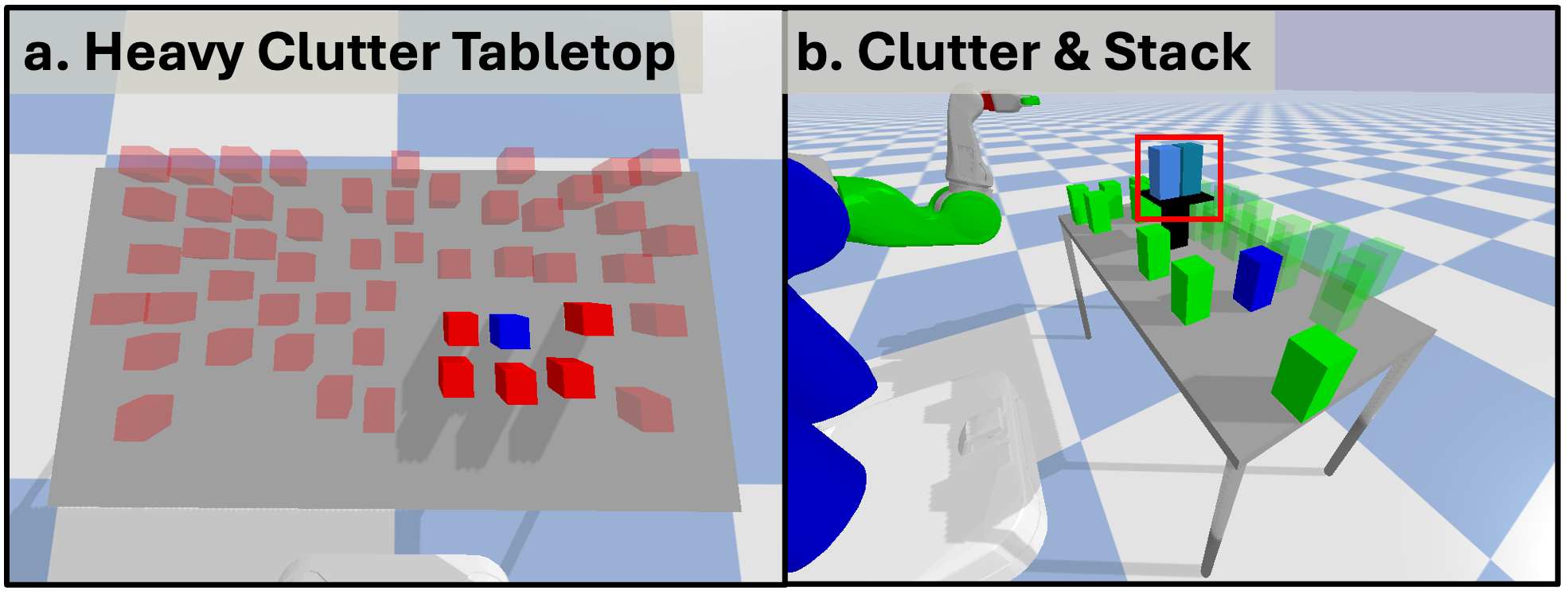
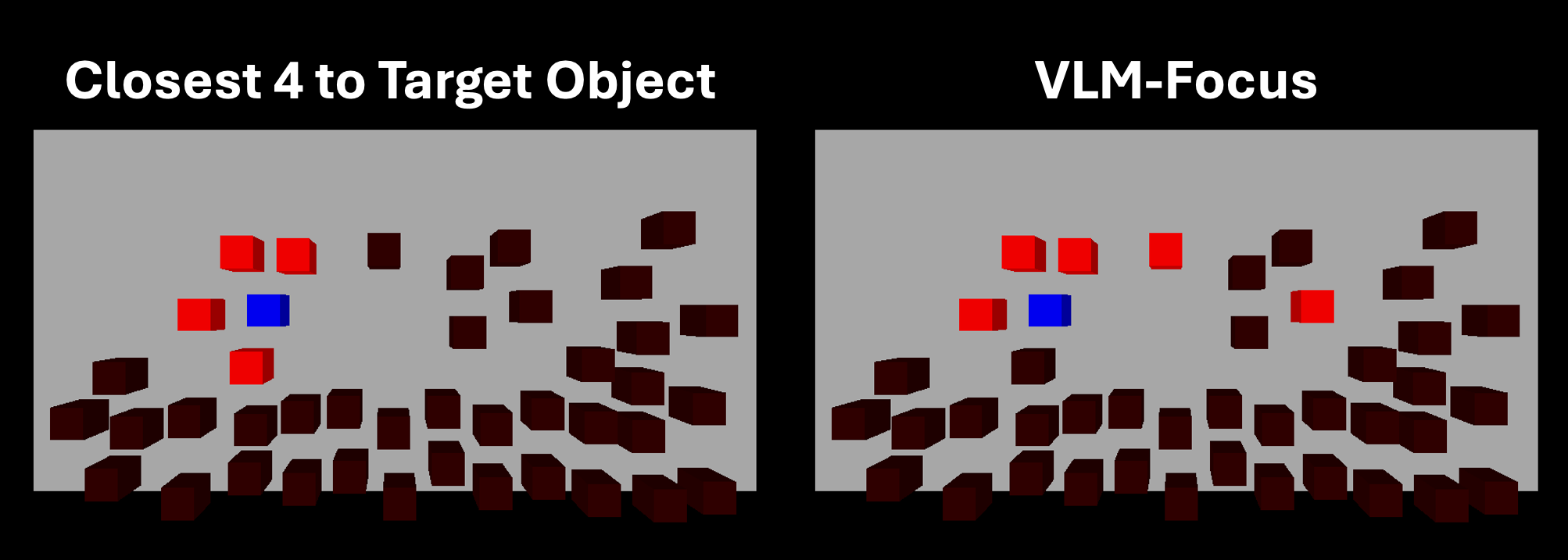
Method
VLM-Focus is a general, task-agnostic framework for constructing task-focused, dynamic scene abstractions
using vision-language models and iterative task feedback. Given a natural language task description and
a scene description, a VLM (GPT-4.1 mini) is prompted to output: (i) a minimal set of
task-relevant objects critical for task completion, and (ii) groups of objects
that may be merged into a single composite entity.
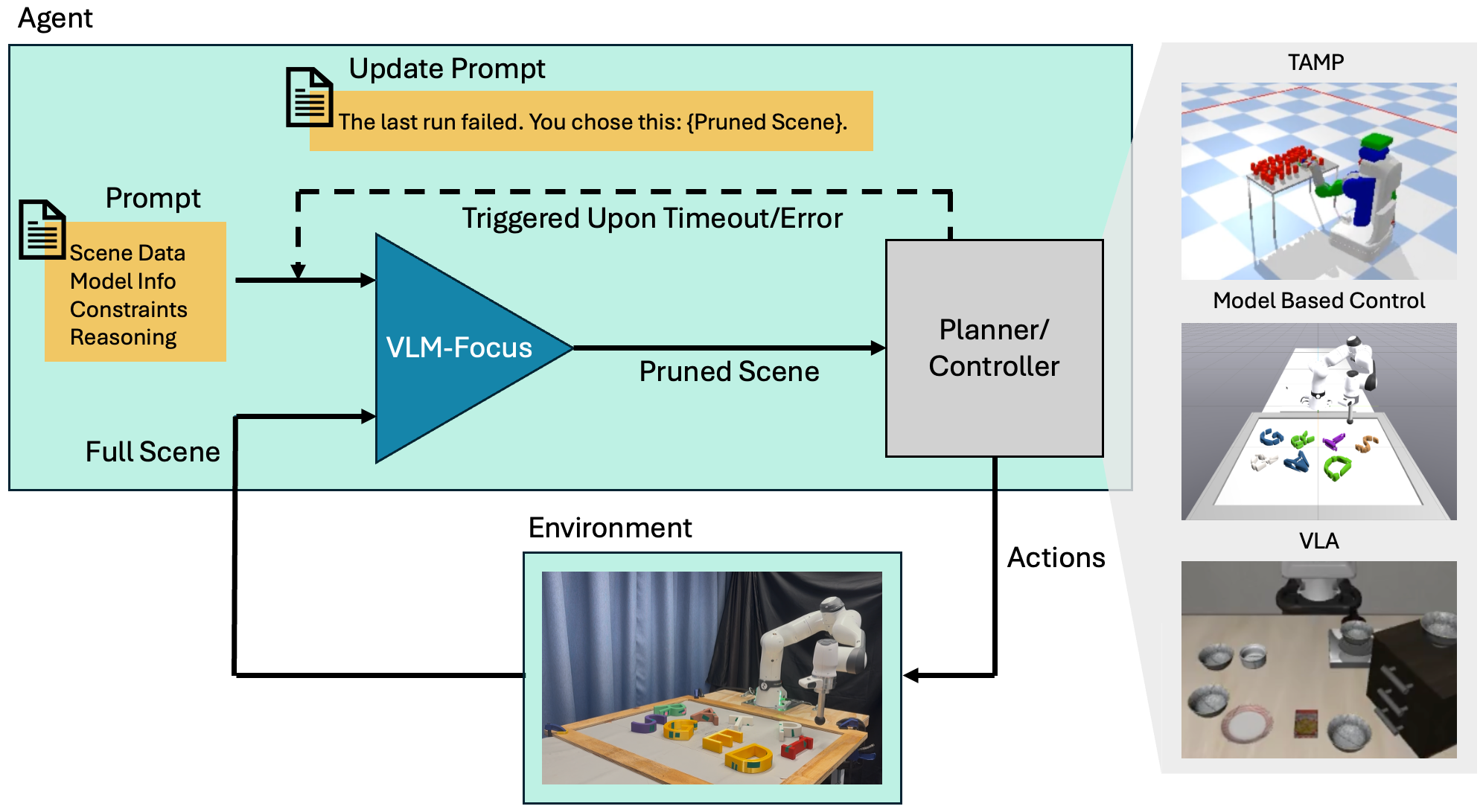
Figure 2. System overview of VLM-Focus. Given a task description via the full scene
and prompt information, VLM-Focus (blue) prunes and merges objects to produce an abstracted scene,
which is passed to the planner or controller (grey). When triggered by failure or timeout, VLM-Focus
revises its scene pruning. This approach generalizes to TAMP, model-based controllers, and VLAs.
✂️ Pruning
Objects excluded from the task-relevant set are omitted from the planner/controller's world model — eliminating unnecessary decision variables (TAMP), contact constraints (MPC), and visual distractors (VLA).
🔗 Merging
Groups of objects that are functionally or dynamically coupled are replaced by a single composite entity whose collision geometry is the union of its members, reducing rigid-body count and contact interactions.
🔄 Closed-Loop Re-prompting
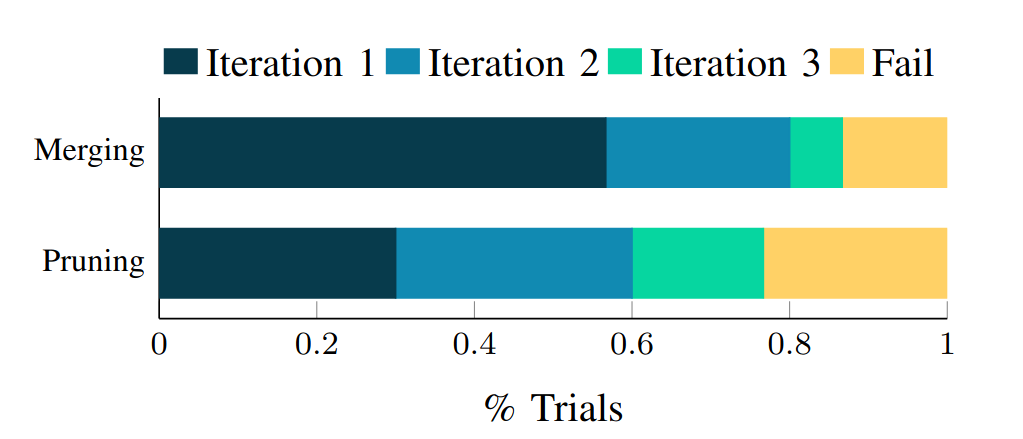
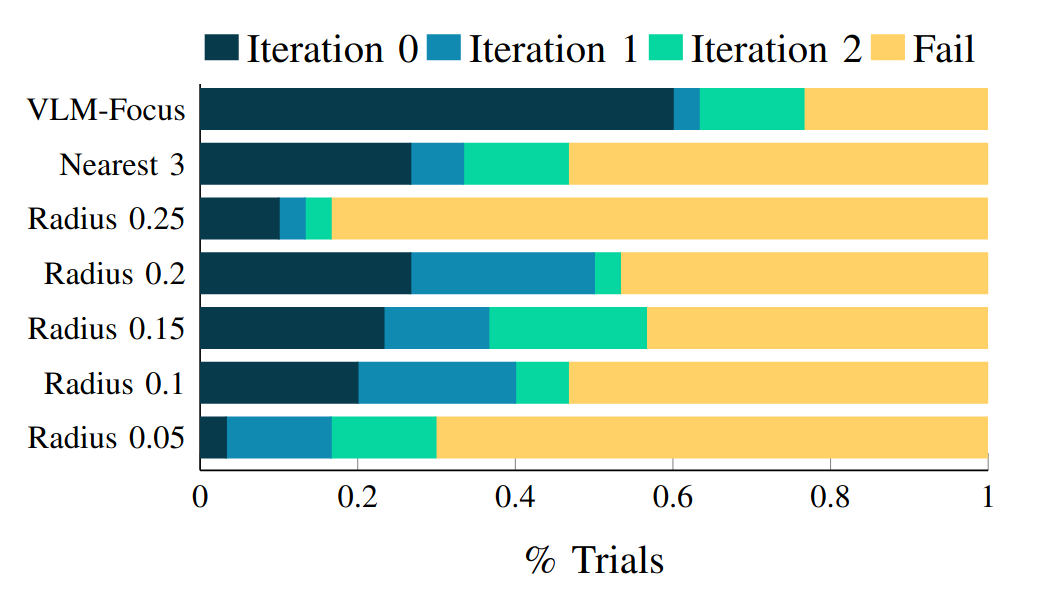
When a downstream planner finds the abstracted scene infeasible or a controller fails, that feedback is passed back to the VLM — which iteratively corrects the abstraction, restoring over-pruned objects or refining merges. This loop is triggered by timeouts or error codes from downstream systems.
Contributions
-
1
A general, task-agnostic method for estimating task relevance using VLMs and constructing task-focused scene abstractions. Closed-loop re-prompting with planning/simulation feedback corrects VLM errors and refines abstractions.
-
2
Integration with three distinct paradigms: (i) Task and Motion Planning (TAMP), (ii) optimization-based contact-implicit control (C3+), and (iii) the π0.5 Vision-Language-Action (VLA) model.
-
3
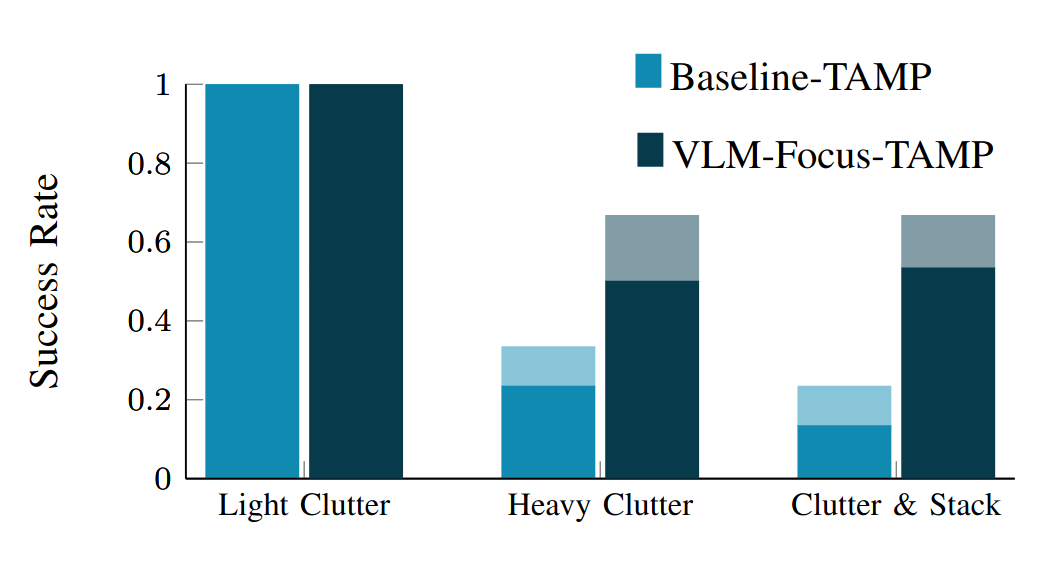
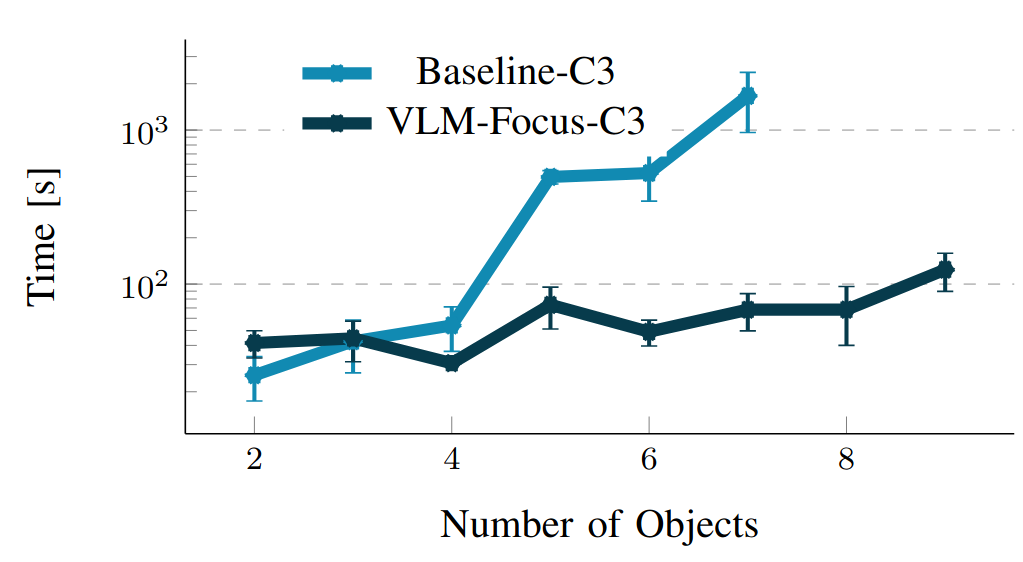
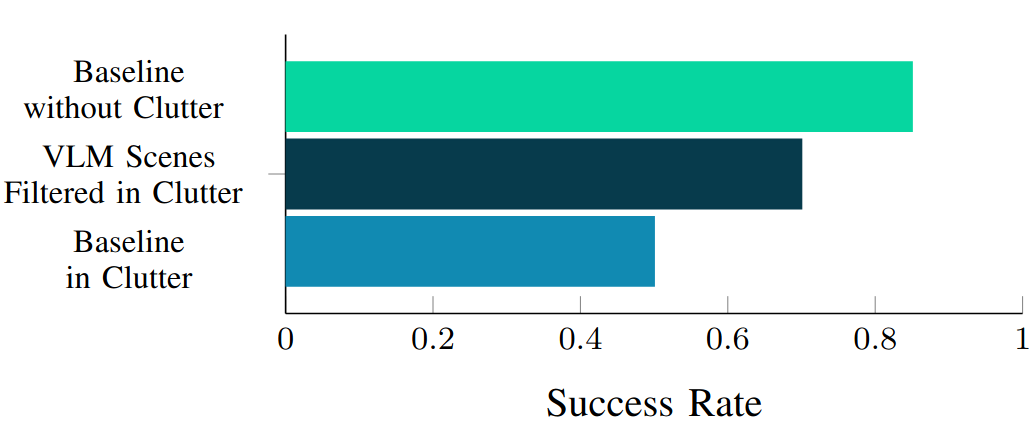
Experimental evaluation in cluttered tabletop settings demonstrating improved scalability, robustness, and efficiency with increasing object count, on both simulation and real hardware.